如何使用GIT进行团队协作(完整版)
Wirtten by : Eric_wu
目录
6. 项目结构、项目描述、使用方式与代码的规范(README、描述与注释)
如何使用git进行团队协作
工具下载
VPN
Git
GitHub desktop
下载详细步骤
VPN
- 梯子地址
- 套餐价格
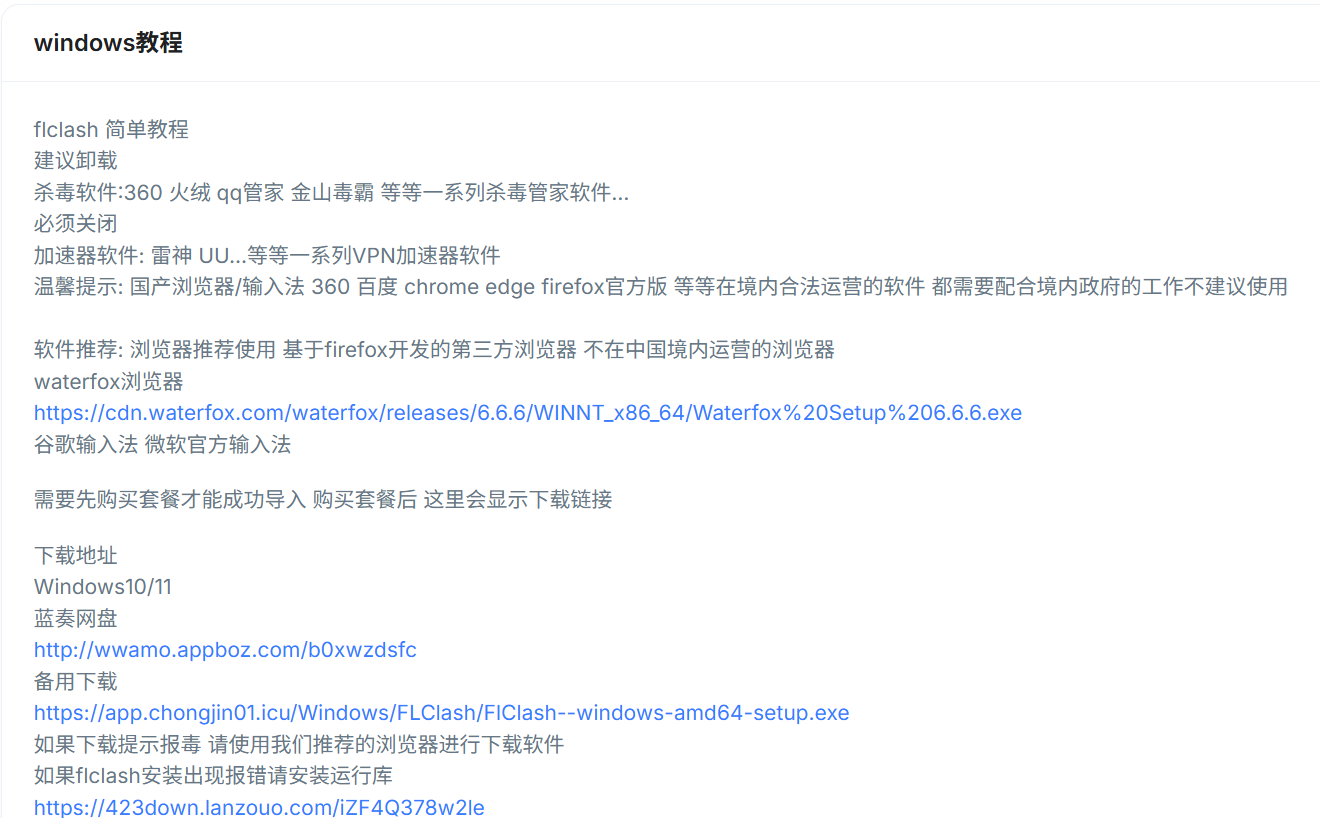
- Windows使用教程
Git
浏览器搜索Git:(下图1)
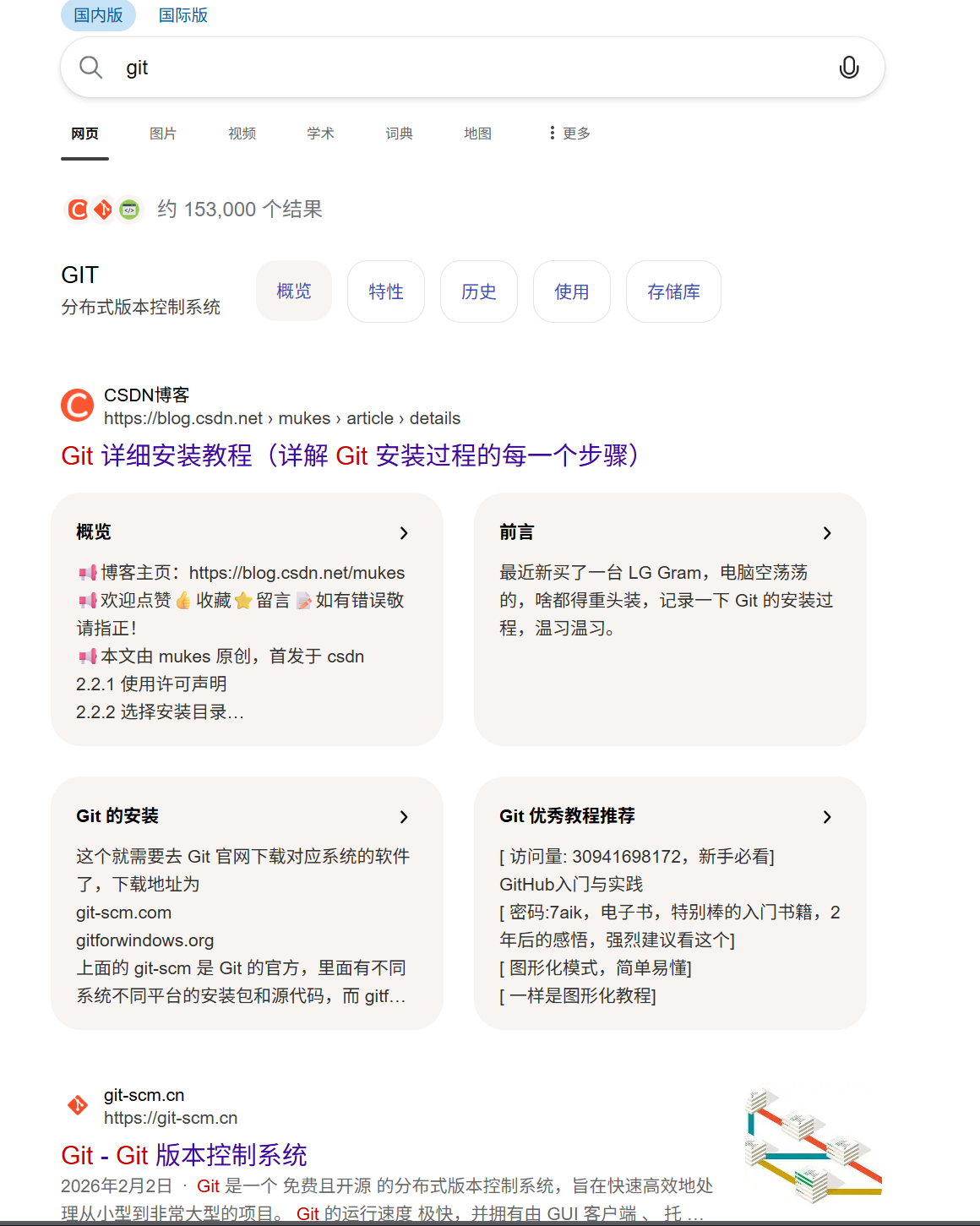
- 浏览器搜索GIT
可以看第一个博客参考下载,也可以自己进第二个官方网址下载。
博客地址:Git 详细安装教程(详解 Git 安装过程的每一个步骤)_git安装-CSDN博客
打开网址后点击Install for Windows:
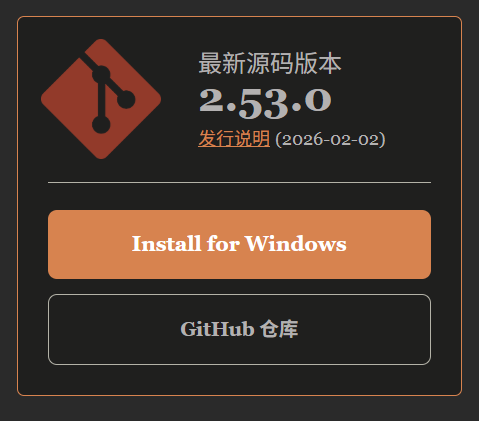
- 主界面的下载栏
选择Git for Windows/x64安装包进行下载:
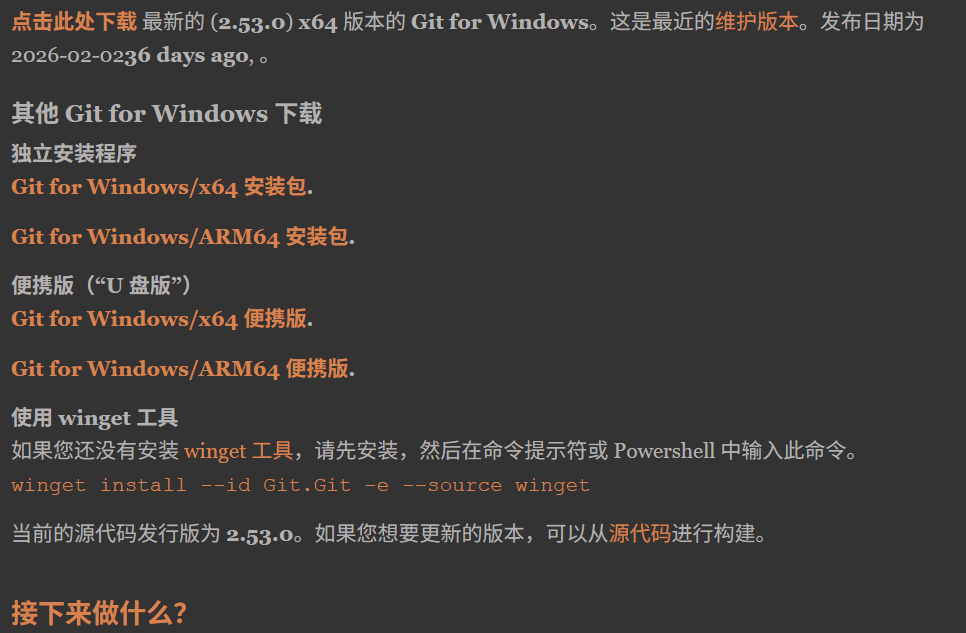
- 下载界面
下载完后根据博客流程安装并配置环境变量。
GithubDesktop
为什么要使用github desktop?
Git官方UI和Bash太难使用,需要记忆太多的代码操作,github desktop可视化,方便使用和回溯。
参考博客:GitHub Desktop 使用入门_github desktop怎么配置-CSDN博客
下载Github desktop
创建并登入自己的github账号
如何创建github账号:
https://docs.github.com/zh/get-started/start-your-journey/creating-an-account-on-github
如何使用?
新建一个本地的仓库
在options中进行登录:
- Options位置
本地新建一个仓库:
- 新建仓库位置
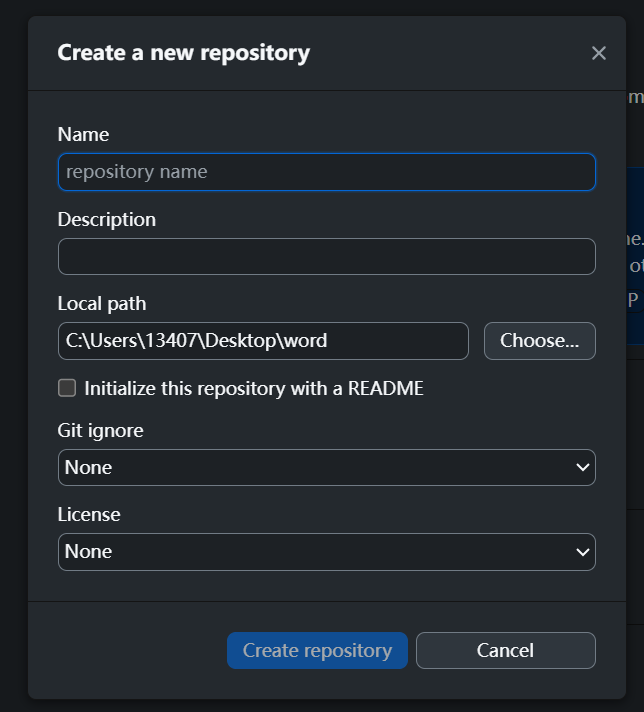
- 新建仓库选项
Name:仓库名称
Description:仓库描述
Local path:本地仓库位置
README:是否创建一个README(仓库的介绍)Markdown格式编码
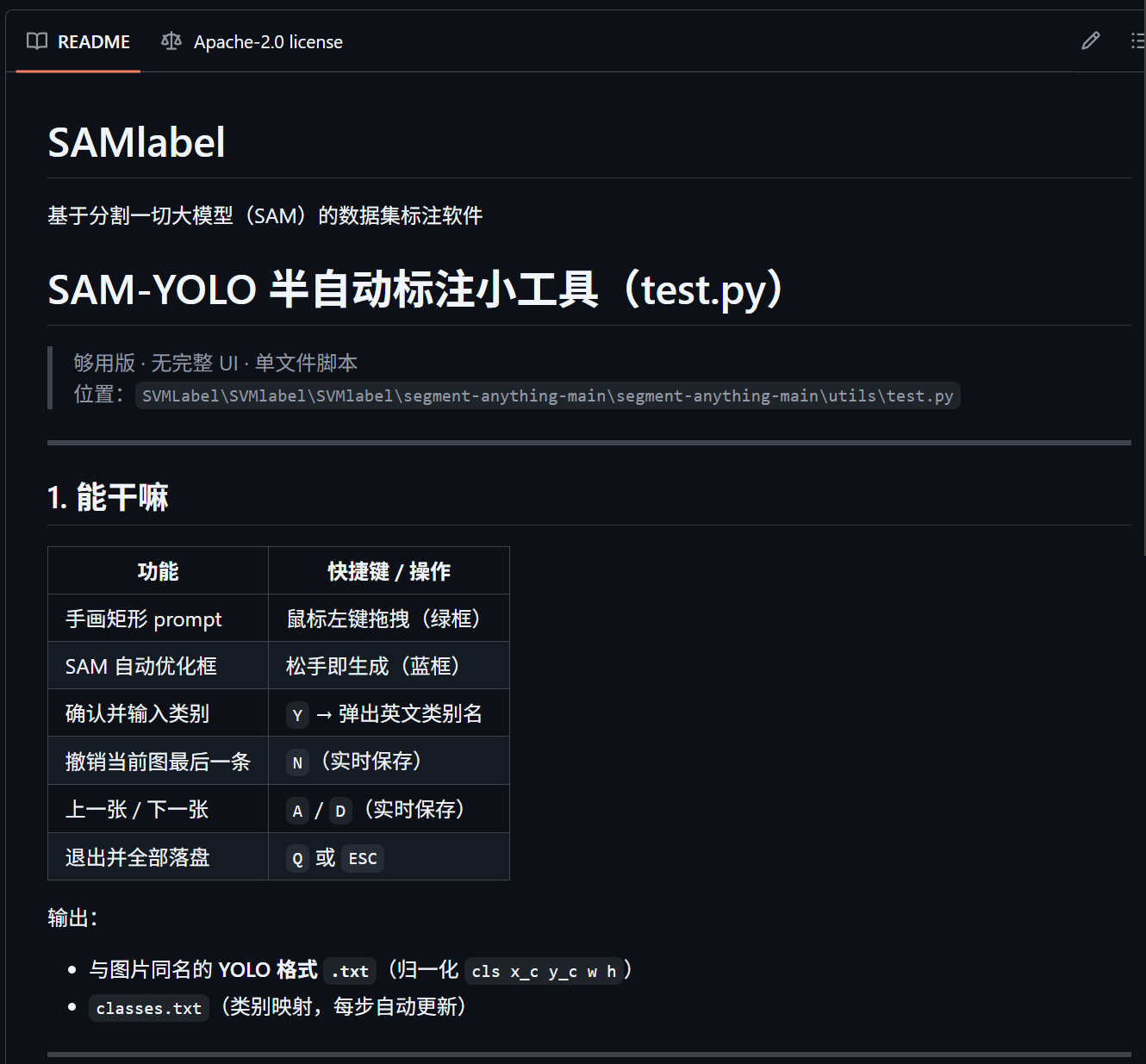
- README案例
Git ignore:在仓库中忽略的文件
License:仓库的开源or闭源协议
这个仓库现在保存在本地中。
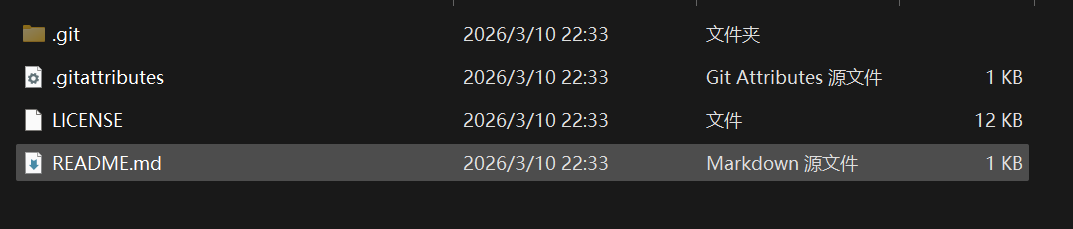
- 仓库文件
.git:隐藏文件:包含版本信息
LICENSE:刚刚添加的协议
README.md:描述文件
- Readme文件的具体内容
如何克隆一个仓库
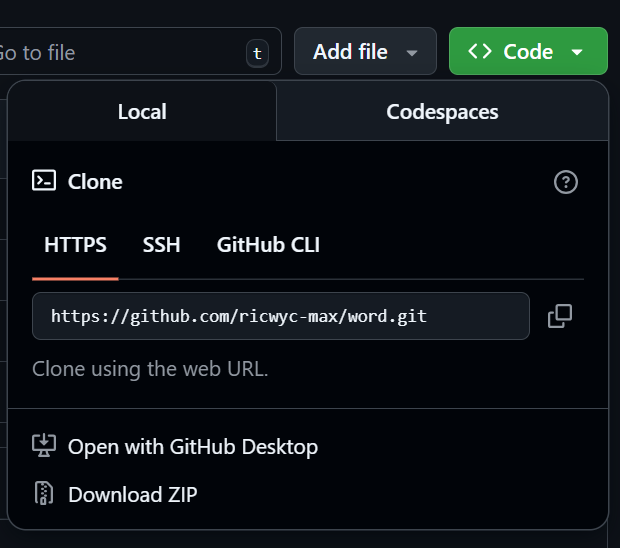
- Local
Clone:克隆
HTTPS:通过网址方式进行克隆(推荐用这个)
GitHub Desktop:通过GitHub Desktop打开
Download ZIP:直接下载ZIP压缩包
把本地仓库删除:
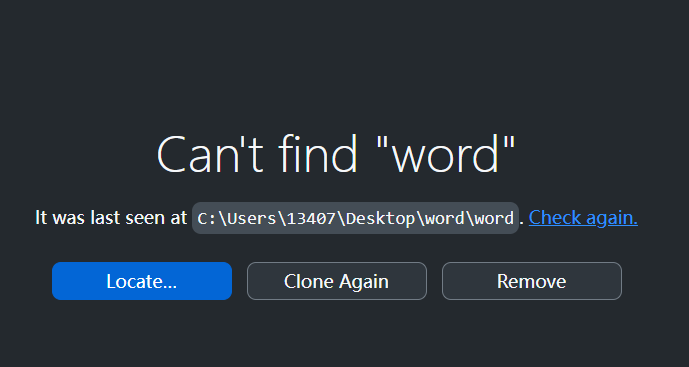
- 本地仓库删除效果
此时本地仓库就没有了,可以Remove掉。
此时,我们复制Clone的这个URL:
https://github.com/ricwyc-max/word.git
我们在File上找到这个Clone repository:
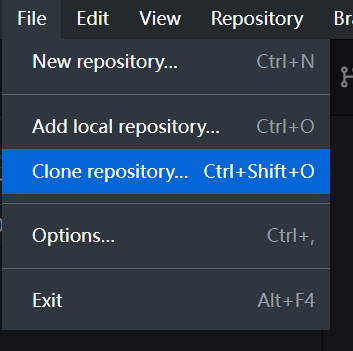
- Clone repository位置
点击进入克隆页面,选择URL:
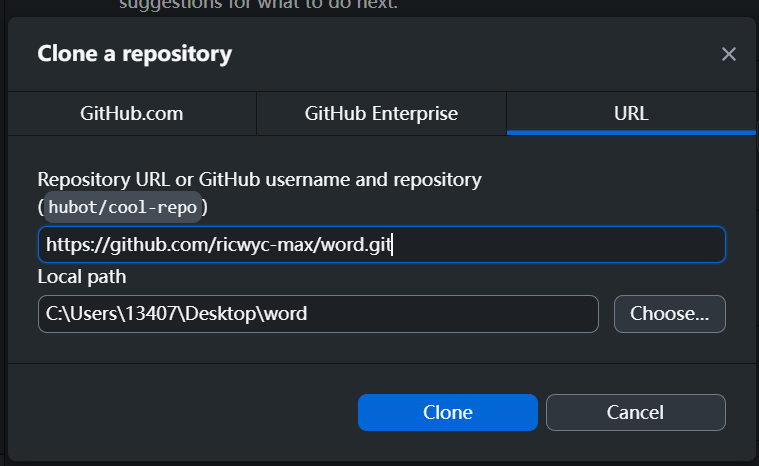
- Clone参数
将刚刚复制的ULR输入地址位置,然后选择我们克隆本地的仓库位置。
选择完成,点击Clone。
- 克隆结果
此时云端的仓库又被拉回本地了。
版本管理
在仓库文件夹中添加1.txt,在github desktop中可以看到我们修改的具体内容:
- 添加1.txt
- 当前仓库位置
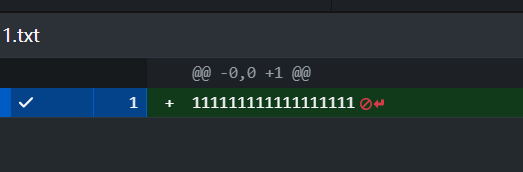
-
修改的具体内容
- 描述栏
第一行:简要的概述
第二行:具体的描述
Commit:提交修改
提交之后点击history:

- History位置
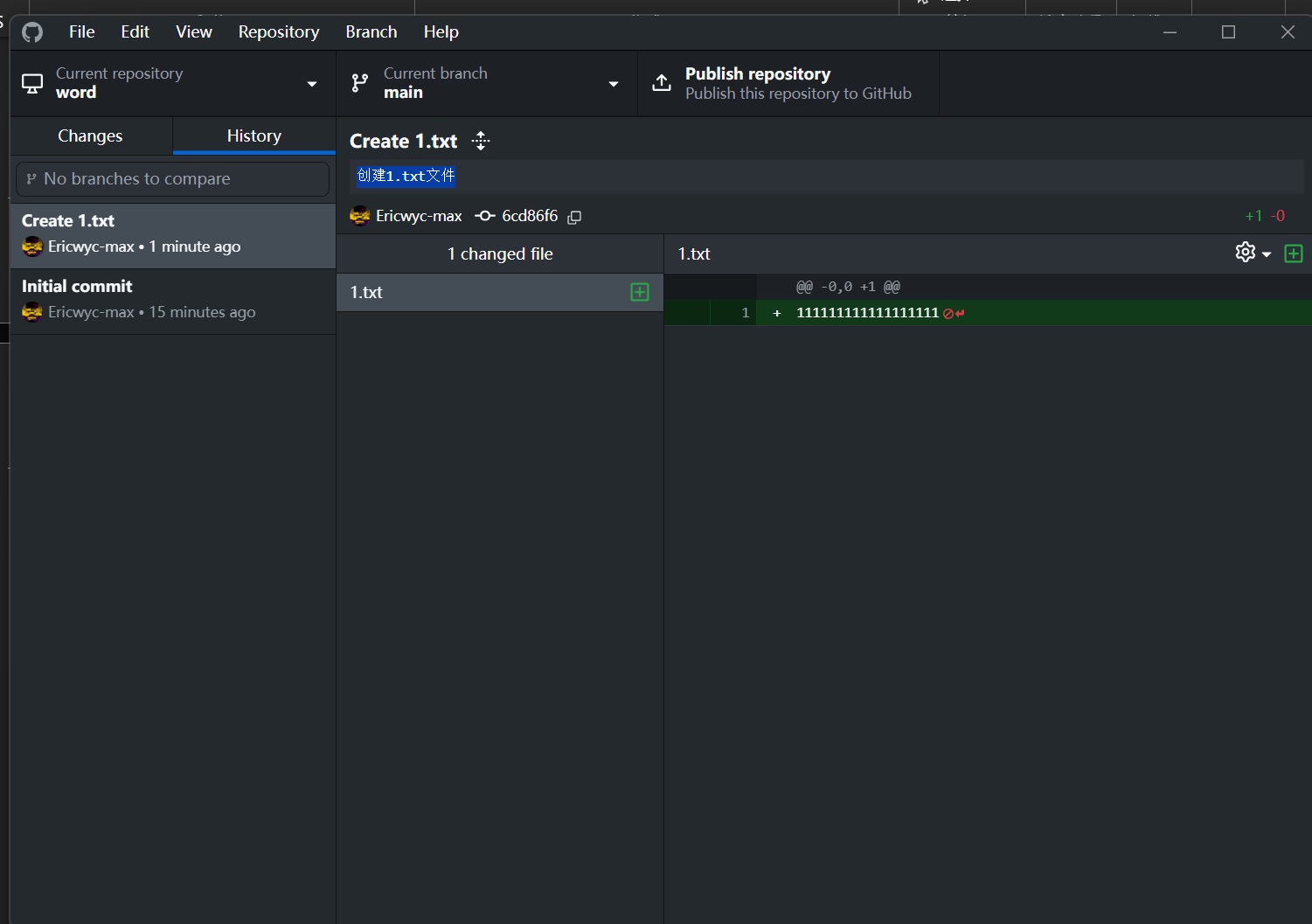
- History效果
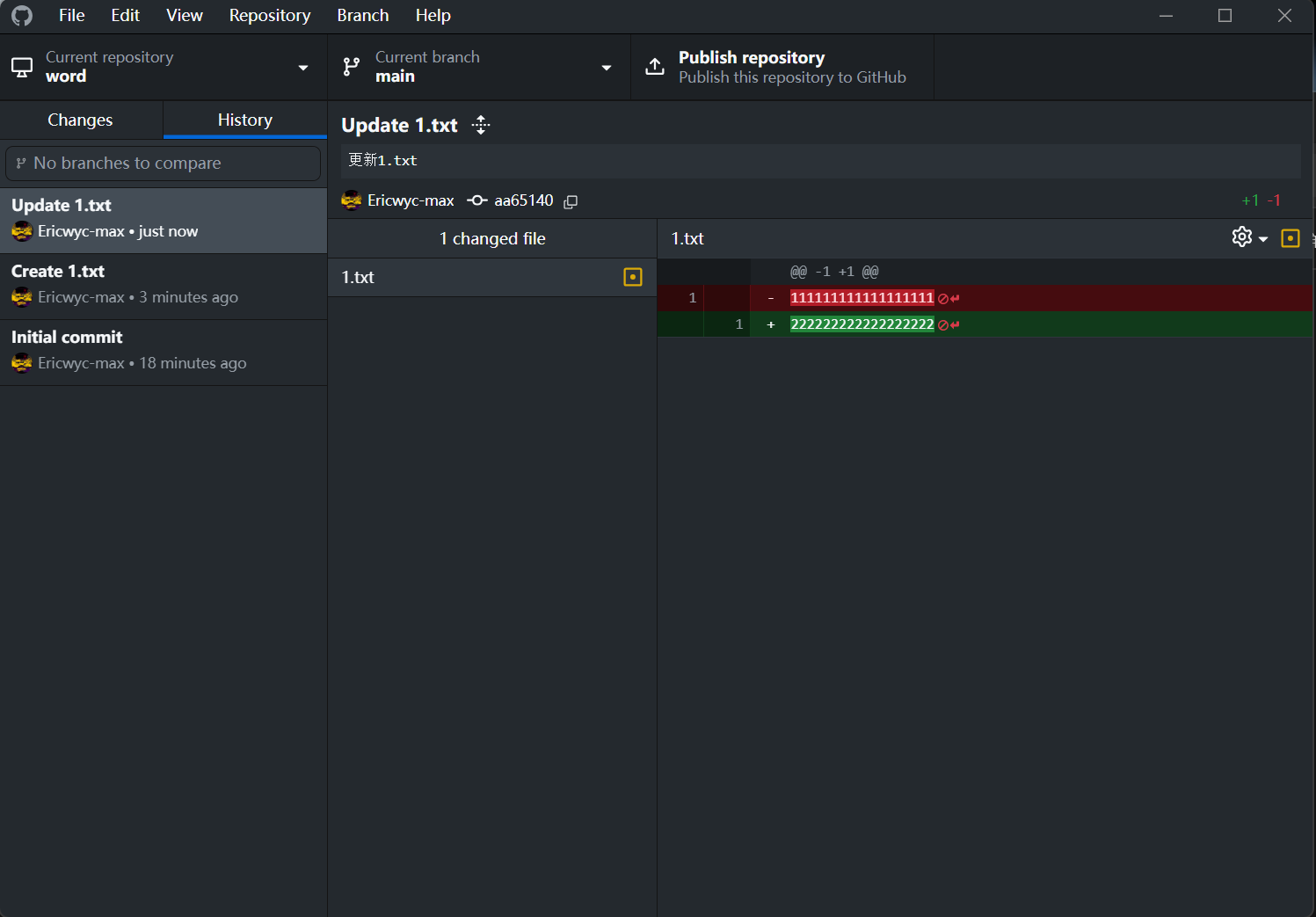
- 更新文件后,history效果
为什么要进行提交修改?
有时候我们写代码的时候,会出现代码写着写着报错了,但是ctrl+z没办法回到原来的版本,这个代码就报废了。
但是,通过git版本管理软件进行管理,我们可以在合适的位置恢复我们的代码,从而避免这种情况的发生。
我们可以在特定的保存位置创建分支,从而恢复之前的代码状况:
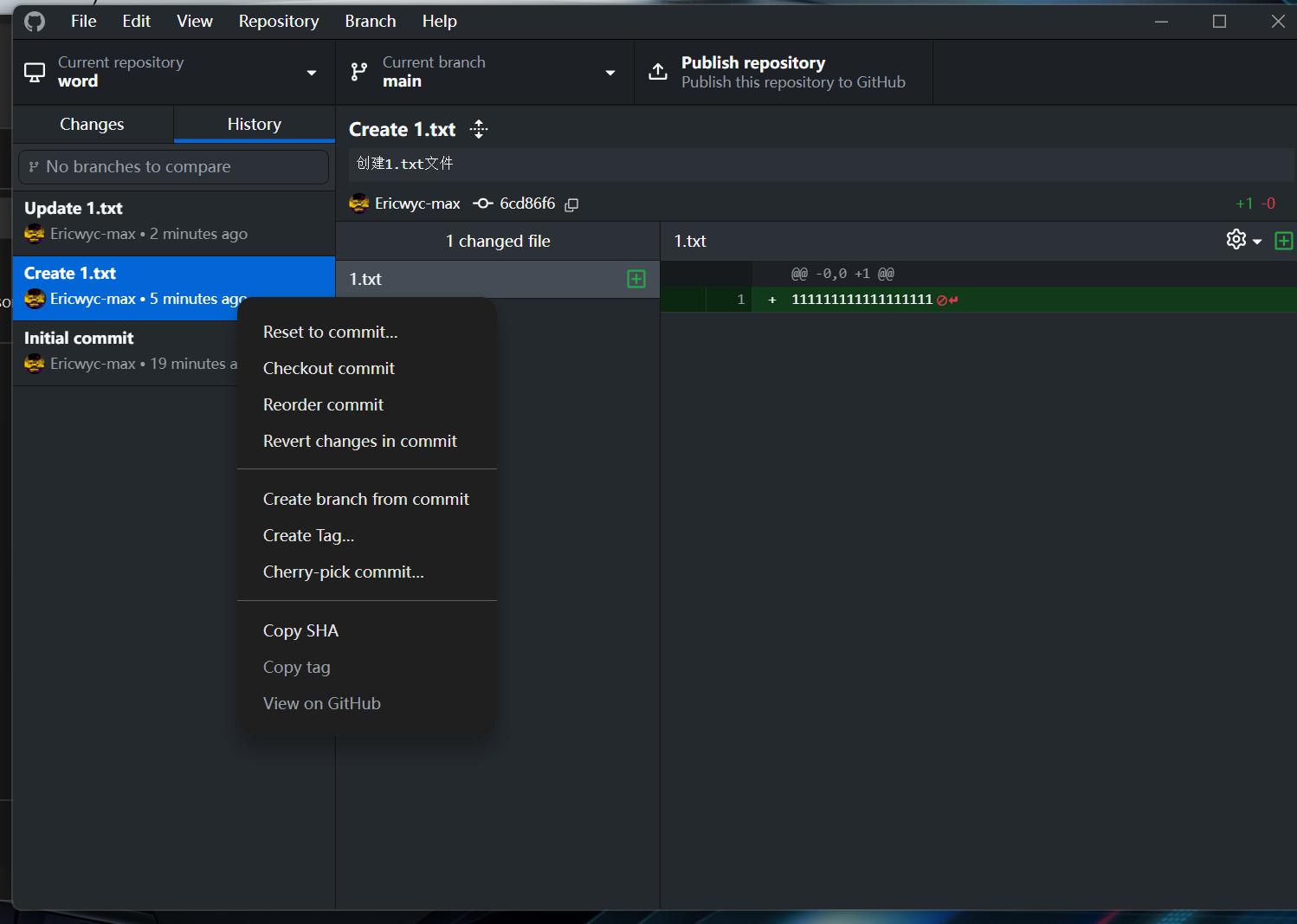
- Create branch for commit位置
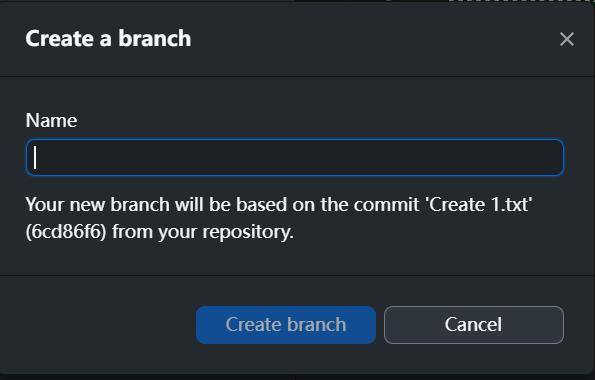
- 为新分支输入名称
我们可以看到Current branch一栏中两个分支:(一个是我们的主分支【main】,还有一个是创建的分支【branch】)
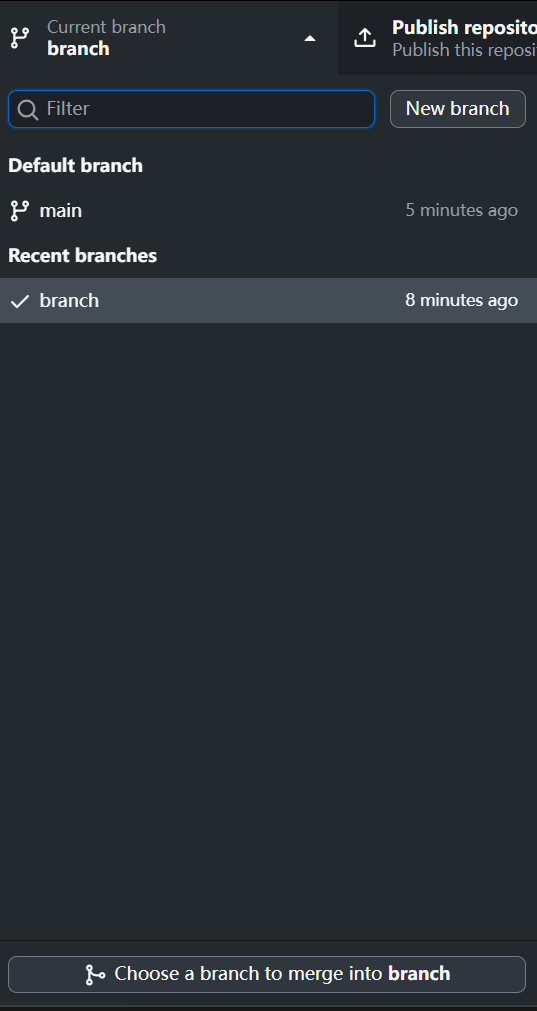
- Current branch一栏中两个分支
选择branch分支,我们可以看到,1.txt回到了原来的位置:
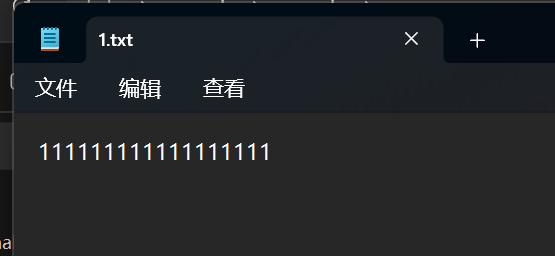
- 文件回到了原来提交Create 1.txt的位置
如果选择main主分支,我们的代码又回到了最新的位置。
云端管理
将仓库上传到云端:
- Publish
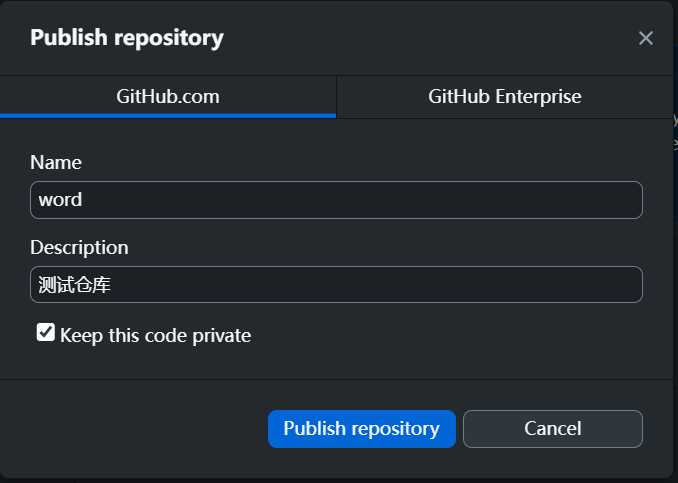
- Publish选项
Name:仓库名称
Description:仓库描述
Keep tis code private:这个代码是否是开放的(如果是开放的,那就是别人可以下载,否则只有自己和共创者能看到)
如何查看?

- View on GitHub位置
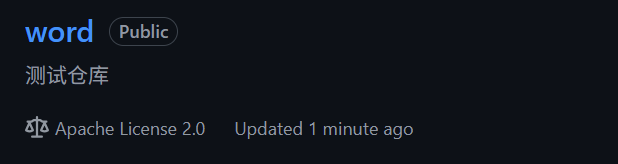
- 测试仓库云端显示
此时我的测试仓库就被拉到云端了!
把个人本地仓库拉到云端的目的:
-
如果是开源仓库,开放下载,给开源社区提供贡献,增加个人影响力
-
如果是私人仓库,代码留档,就可以将团队成员添加到共创者中,共创者就可以下载,远程修改仓库,从而引出代码协作这个功能
代码协作
在云端仓库位置,可以添加共创者:
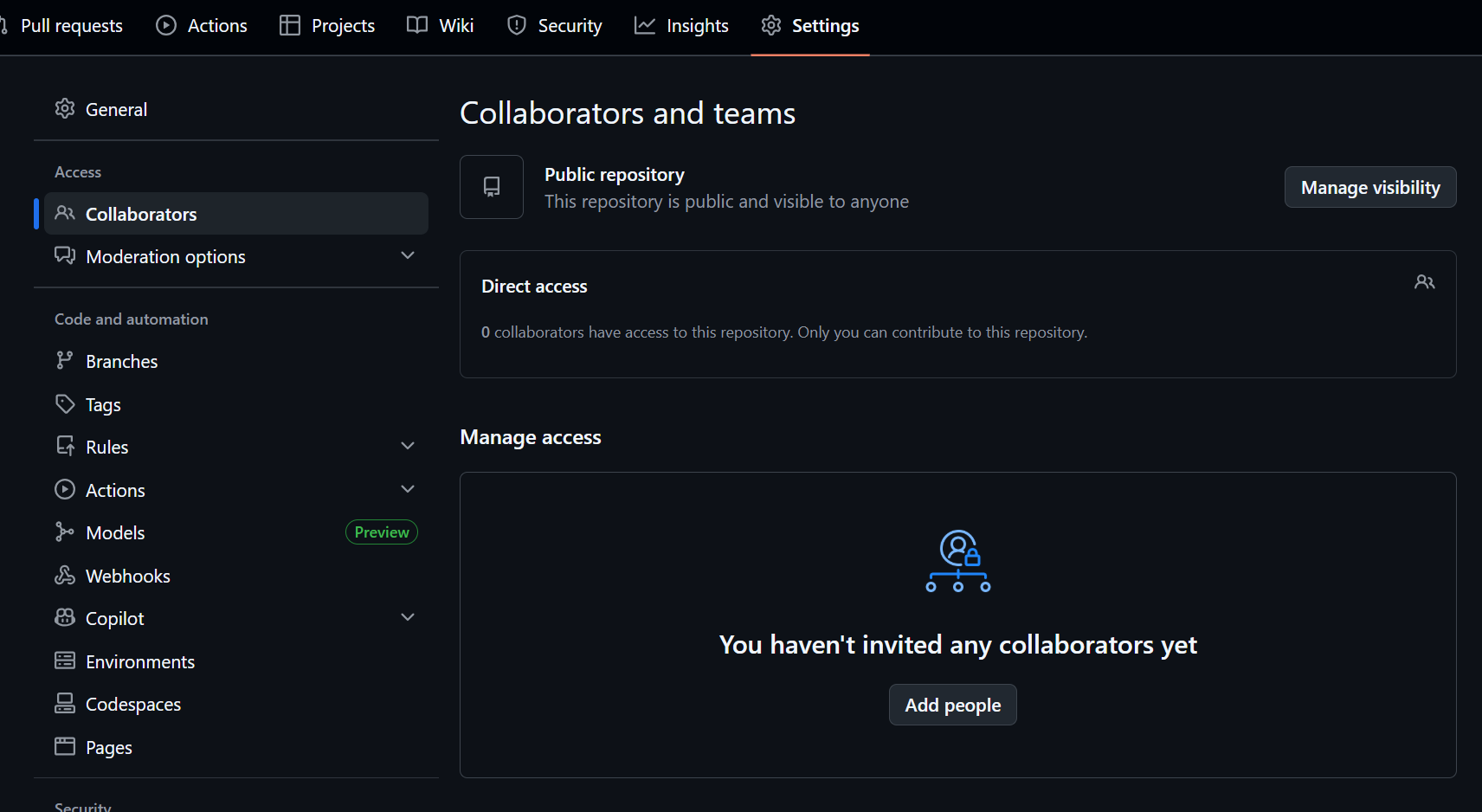
- 添加共创者位置
云端位置,Settings->Collaborators->Add people
在没有添加共创者的情况下,只有你(项目所有者)能够向云端传送代码。其他人向上传输代码都会报错,只能够在其他人的云端创建一个你的云端仓库的副本(fork),再上传到其他人的云端副本上。
在做提交的过程中,就会出现提示:
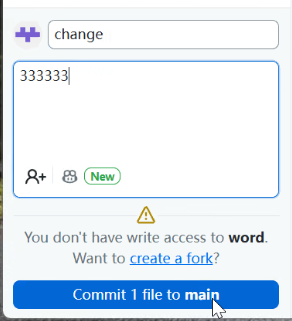
- 没有写入权限提示
真正尝试提交仓库,就会报错:
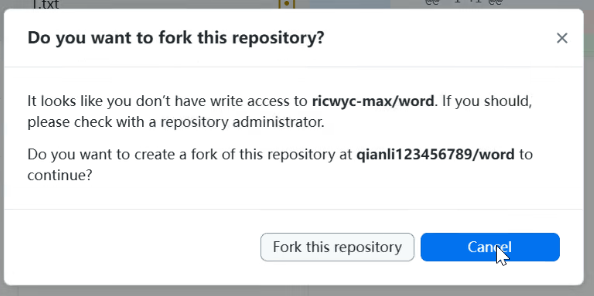
- 没有写权限报错
有没有什么办法能够让别人能够修改我的仓库?
我可以把他人加进共创者中:
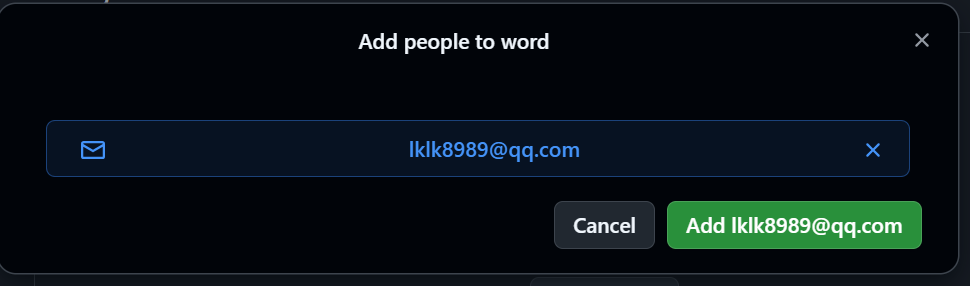
- 输入他人账号,添加权限
点击添加:
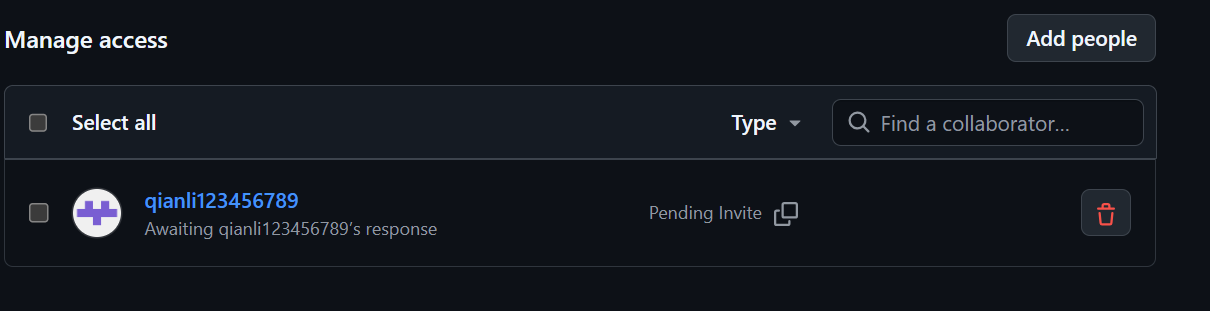
- 添加后看到权限情况
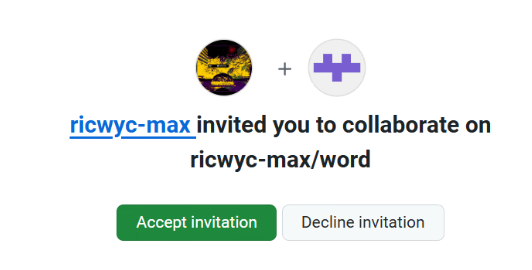
- 接收邀请
此时他人再推送,就可以推送了!
这个推送,推送到的是我的仓库,不是他人的仓库!
此时,共创者进行了修改,将我的云端仓库修改成为了333333:
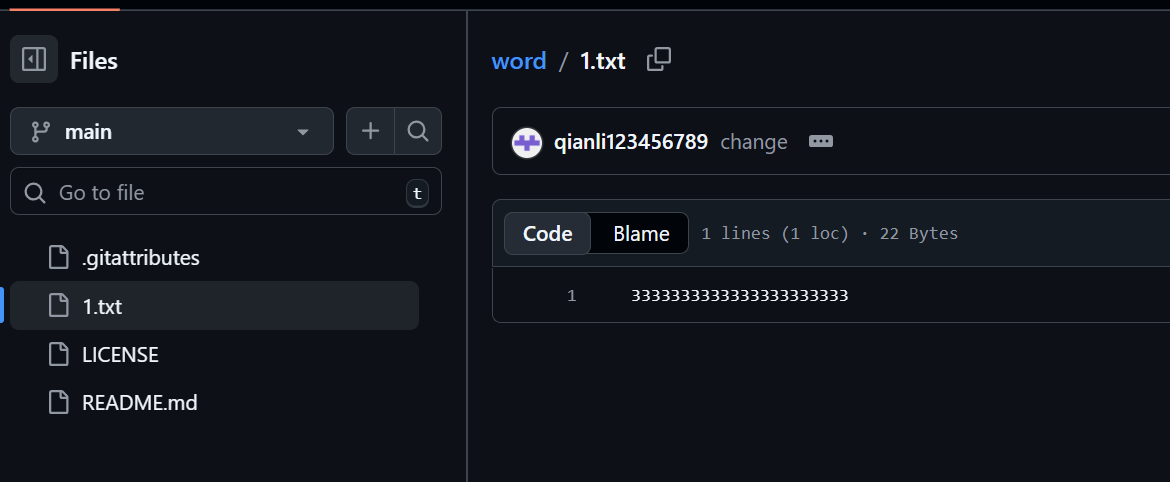
- 云端仓库情况
但是,我的本地仓库还是22222:
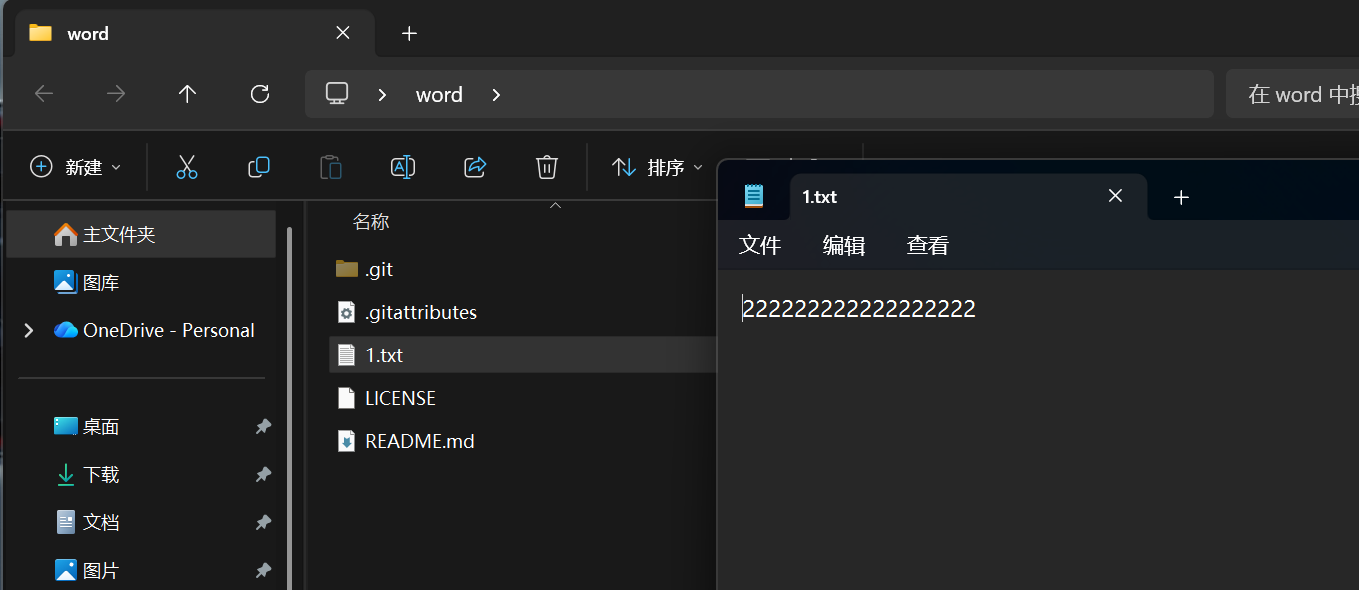
- 本地仓库
怎么够更新我的本地仓库,让共创者的修改同时反映到本地呢?
我们点击Fetch origin:
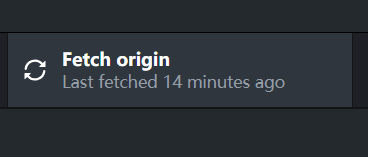
- Fetch origin
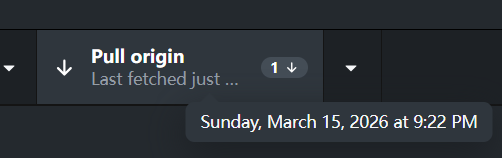
- 仓库搜索到了一个变化(提交)
再点击一次,把这个共创者的提交拉回到本地:
- 点击后效果
此时查看,就可以在本地看到共创者的修改,并且看到谁修改了仓库、修改了什么内容,同时我们本地的仓库也会进行更新:
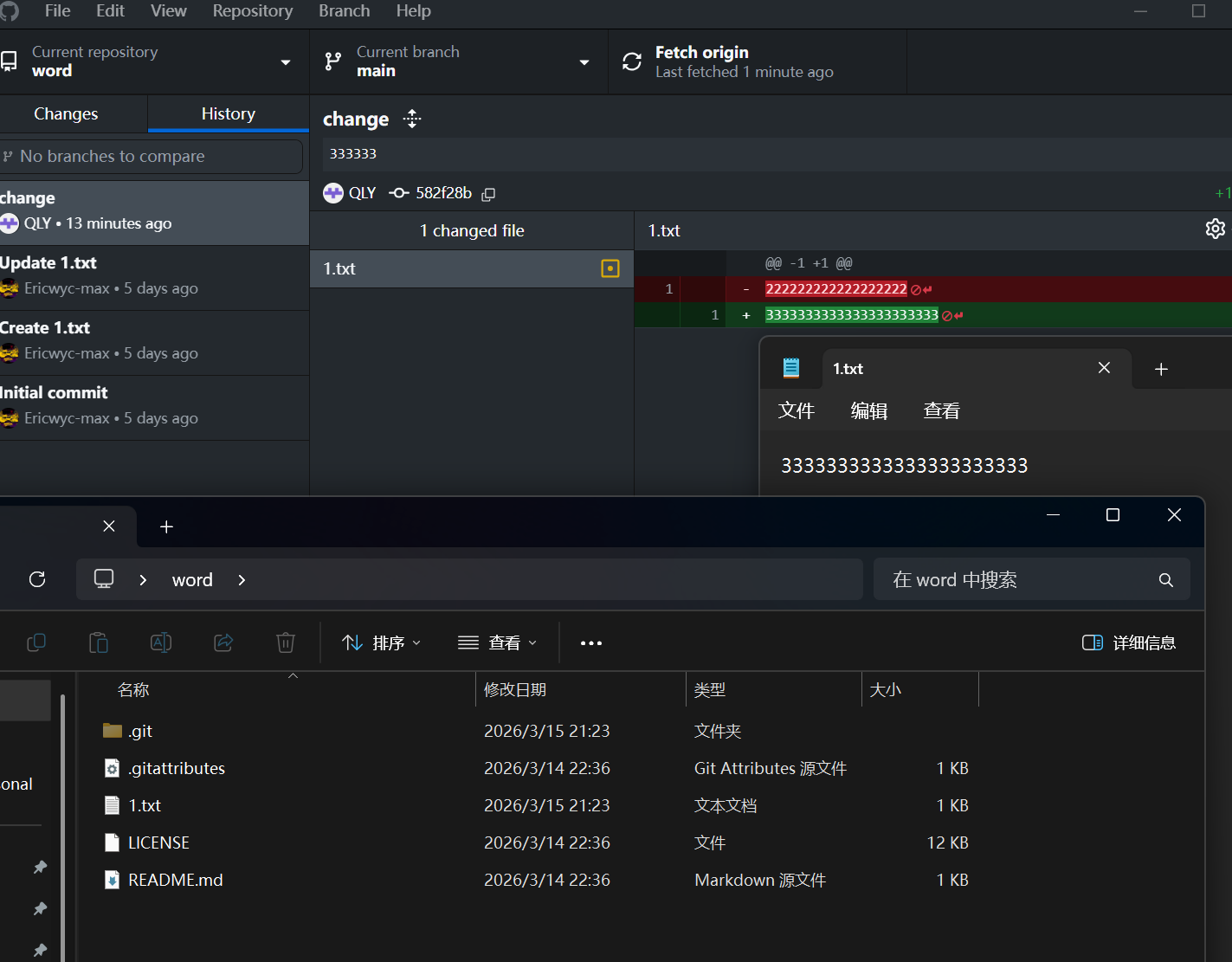
- 本地仓库更新
为什么需要这个功能?
比方说我们5个人需要共同写一份代码,但是互相的修改可能会有冲突,我们没有办法获取到最新的代码状态,通过这种方式,我们可以相互看到各自的代码,同时了解整个项目的运行进度。
项目结构、项目描述、使用方式与代码的规范(README、描述与注释)
README:项目介绍,库的文件结构,使用方式及基本介绍
目前:
-
我们要完成的目标(每个人领取一个任务,想办法做成)
-
目前的整个项目结构
-
修改更新的部分
代码规范:
"""
自己搭建的网络块文件
包括:
1、基本残差网络(分前向激活和非前向激活版本)\
2、瓶颈结构残差块(Bottleneck Block)(分前向激活和非前向激活版本)\
"""
代码最前面要有注释:描述整个文件具体做什么,有什么功能(概述)
class ResidualBlock(nn.Module):
"""
基础残差块(ResNet风格)
包含跳跃连接(Skip Connection),解决梯度消失问题
包含前向激活(preactivated),解决100层以上网络训练困难问题
一次添加两个-三个(多一个下采样)卷积层
每个类前面也有注释:描述这个具体类是干什么的。
包括类有什么功能,这个类有什么初始化参数,这个类有什么方法。(概述)
*#初始化定义\*
def __init__(self, in_channels, out_channels, stride=1,downsample=None, activation=**'relu',preactivated=False):
"""
tip:输入通道必须和输出通道匹配,不然,没法相加 : y = f(x) + x
[f(x)与x的通道必须匹配]
in_channels:输入通道数
out_channels:输出通道数
stride:步长
downsample:
下采样层(尺寸/通道不匹配时使用),需要时传入卷积块,不需要为None,默认None\
activation:激活层,只有relu和leaky_relu\
preactivated:是否前向激活,需要为True,不需要为False(Pre-activation/ResNet-v2风格)*
每个初始化参数是什么,有什么用。
if not preactivated:
# ========== 标准 ResNet (ResNet-v1/v1.5) ==========
"""
顺序:
Conv(1x1) → BN → ReLU →
Conv(3x3, stride) → BN → ReLU → ← stride在这里(ResNet-v1.5推荐)
Conv(1x1) → BN → Add → ReLU
"""
self.conv1 = nn.Conv2d(in_channels, mid_channels, kernel_size=1,
stride=1, padding=0, bias=False) # 降维
self.bn1 = nn.BatchNorm2d(mid_channels)
self.conv2 = nn.Conv2d(mid_channels, mid_channels, kernel_size=3,
stride=stride, padding=1, bias=False) # 特征提取+下采样
self.bn2 = nn.BatchNorm2d(mid_channels)
self.conv3 = nn.Conv2d(mid_channels, out_channels, kernel_size=1,
stride=1, padding=0, bias=False) # 升维
self.bn3 = nn.BatchNorm2d(out_channels)
else:
# ========== 预激活 ResNet-v2 (Pre-activation) ==========
"""
顺序:
BN → ReLU → Conv(1x1) →
BN → ReLU → Conv(3x3, stride) →
BN → ReLU → Conv(1x1) → Add
"""
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = nn.Conv2d(in_channels, mid_channels, kernel_size=1,
stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(mid_channels)
self.conv2 = nn.Conv2d(mid_channels, mid_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(mid_channels)
self.conv3 = nn.Conv2d(mid_channels, out_channels, kernel_size=1,
stride=1, padding=0, bias=False)
我的每一部分代码块具体完成的什么内容。
流程书写:
if __name__ == '__main__':
# ==================== 像 tf.keras.Sequential 一样直接搭 ====================
# ============================== 模型定义 ===================================
#使用 OrderedDict(给每层命名,更像TF)
model = nn.Sequential(OrderedDict([
('resBlok', ResidualBottleneckBlock(512,30,512,preactivated=True)),
('dowmSample',nn.Conv2d(512, 256, kernel_size=1,
stride=2, padding=0, bias=False))
]))
# ==========================================================================
# 可以像字典一样访问
#print(model.block1) # 访问特定层
# 直接使用
#x = torch.randn(2, 3, 224, 224)
#output = model(x) # 自动顺序执行,无需forward
#print(output.shape) # [2, 10]
# ================================== 打印模型架构 ============================
# 1、类似 model.summary() 的表格输出
#summary(model, input_size=(512, 224, 224), device='cpu')#(输入通道,输入w尺寸,输入h尺寸)
# ================================== 打印模型架构 ============================
# 2、torchinfo(推荐,信息更丰富)
# 输出包含:
# - 每层的输入/输出形状
# - 参数量
# - 乘加运算量(FLOPs估算)
# - 内存占用
'''
sum(model,
input_size=(2,512, 224, 224), # (batch, channels, H, W)
col_names=["input_size", "output_size", "num_params", "kernel_size", "mult_adds"],#显示的列
col_width=20,#每列显示的宽度
row_settings=["var_names"],#行的显示设置
verbose=1)
'''
在做方法定义时候,最重要的不是你里面具体注释了什么。里面的注释是给做这个方法的人看的,但对使用者来说,我只需要知道这个方法,输入是什么、输出是什么就行了。
- README提交格式
Summery:概述提交的内容
Description:具体描述提交的内容
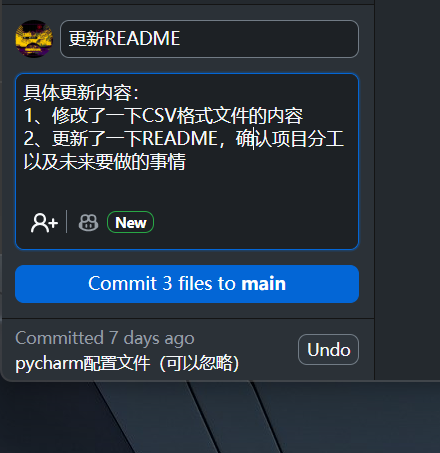
- 提交描述格式